
저번 주에 겨우겨우 설치했던 Pycaret, 기억하시나요?
파란만장 pycaret 설치기
pip install pycaret error
ideal-dominate.medium.com
이렇게 어렵게 설치한 친구인데, 100% 활용해봐야겠죠! 저희 DB에 있는 데이터를 활용해서 파이캐럿을 돌려보도록 하겠습니당 :) Pycaret.classification, pycaret.regression 중에서 저는 회귀분석을 통한 예측, regression을 사용해보았습니다!
0. 넣을 데이터 전처리
무작정 파이캐럿을 import 하기 전에, 넣을 데이터를 전처리해보도록 하겠습니다! 제가 항상 주장하는 전처리의 중요성, 제 글을 열심히 보시는 분들은 다들 알고 계시겠죠😉
항상 그랬듯 사내 DB를 MySQL 연결을 통해 불러오고, (너무 꾸준글이라 생략하겠습니다!) 전처리를 해보겠습니당.
배당률 데이터가 추가되었기 때문에, 이 배당률 데이터를 활용하기 위해 지난번과 같이 5월 19일 이후 경기들, J리그와 K리그 경기들을 필터링해서 담아볼게요!
#필요한 열들만 가져오기
raw = df[['team','date','competition','home','away','tactics','goals',
'goals_cons','xg','ball_possession','result_pts','weather',
'home_odd','away_odd','draw_odd']]#K리그, J리그만 가져오기
KJ = raw[(raw['competition']=='Japan. J1 League') | (raw['competition'] == 'Korea Republic. K League 1')]#5월 19일 이후 경기들만 가져오기
day_str = '2021-05-19'
day = pd.to_datetime(day_str)
KJ = KJ[KJ['date'] >= day]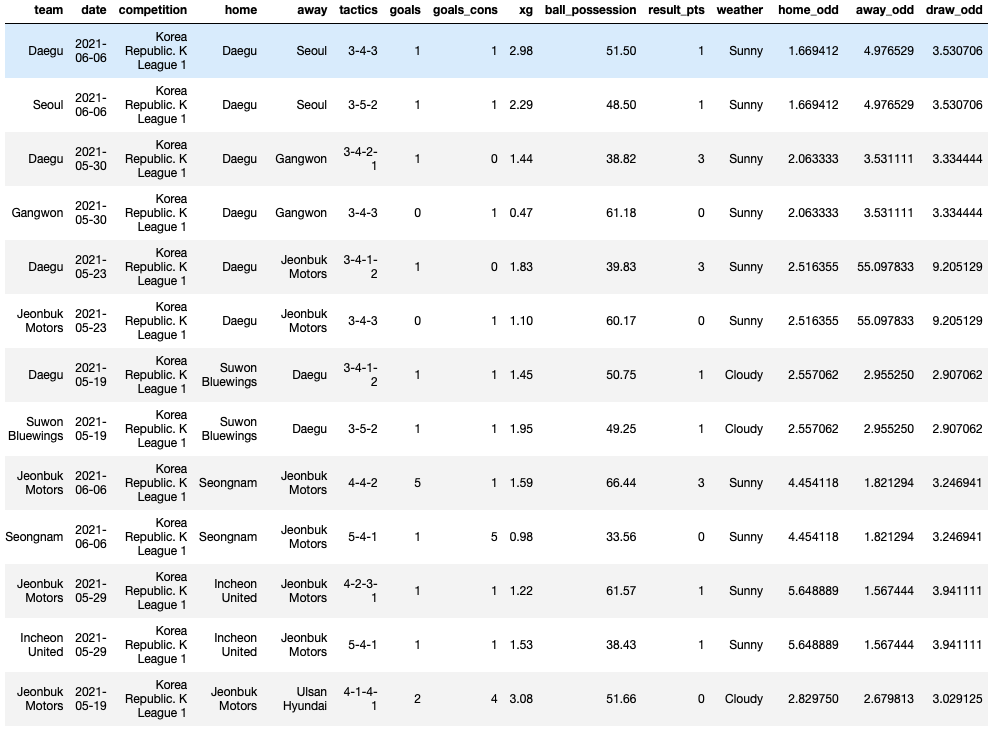
정말 마지막으로, 문자형 데이터를 연속형으로 바꿔주기 위해 get_dummies를 추가로 사용해주도록 하겠습니다! 날씨와 포메이션을 바꿔주었어요.
#연속형 변수로 바꿔주기
KJ =pd.get_dummies(columns=['tactics'], data=KJ)
KJ =pd.get_dummies(columns=['weather'], data=KJ)여기까지 해주면, 전처리는 마무리됩니다!
1. Pycaret.regression 시작하기
설치는 저번 포스팅에서 마무리했으니, 바로 import 해볼게요!
from pycaret.regression import *참 쉽죠?
2. 불러온 pycaret 셋업하기
앞서 전처리 한 데이터를 넣어서 모델을 설정해보도록 하겠습니당.
sup = setup(KJ, target = 'result_pts', train_size = 0.8전처리한 데이터(KJ)를 넣고, 예측할 목표(result_pts) 특정해주고, 전체 데이터를 80:20으로 나눠 train/test 하기 위해 train_size는 0.8로 설정해주었어요! 세부 파라미터는 직접 해보시는 여러분들이 바꿔주시면 됩니다 ;)
3. 모델 비교하기
파이캐럿의 가장 큰 용도, 수십개의 머신러닝 모델을 자동으로 돌려서 가장 효과적인 모델과 파라미터를 찾아준다는 것이죠! 그래서 설정을 마치고, 바로 모델들을 비교해보도록 하겠습니다.
comp = compare_models(sort = 'RMSE')간단하게 compare_models() 함수를 이용해 많은 모델들을 RMSE를 기준으로 비교할 수 있습니다! RMSE는 기본적으로 오차를 중심으로 계산하는 항목이라, 작을 수록 좋은 값이라고 할 수 있어요.
- 여기서 정확도를 측정할 수 있는 척도로 사용한 RMSE는, 추후에 다른 기준들과 함께 설명하는 포스팅을 작성해볼게요. 수식이 조금 등장할 예정인데, 호옥시 수포자이신 분들이 있더라도…꼭 봐주세요🥺
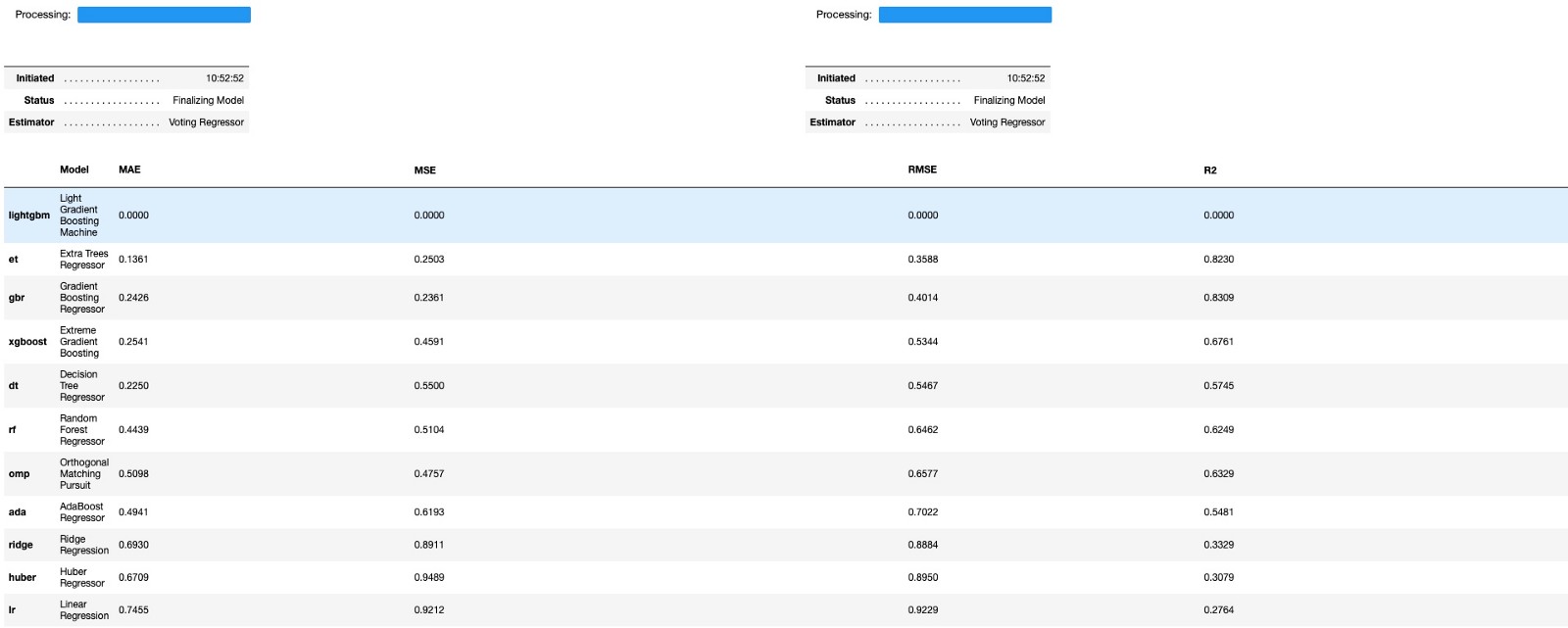
저는 상위 3개의 모델만 사용해 볼 예정이에요. RMSE를 기준으로 정렬해서, 작은 값부터 표시되는데 가장 위에있는 lightgbm은 모든 항목이 0.000으로 표시되는걸 보니, 아무래도 오류가 생긴 것 같아요. 제 데이터에 문자형 데이터가 포함되어있어서 그런걸까요? 흠.. 아무튼, 그 아래부터 3가지를 사용해보도록 하겠습니다!
4. 모델 생성
가장 효과적이라고 하는 top3 모델을 생성해보겠습니다. 역시나 간단하게 한 줄로 가능해요! cross_validation을 False로 설정한 이유는, 앞서 모델을 비교하며 이미 이 과정을 거쳤기 때문입니다!
var = create_model('model', cross_validation = )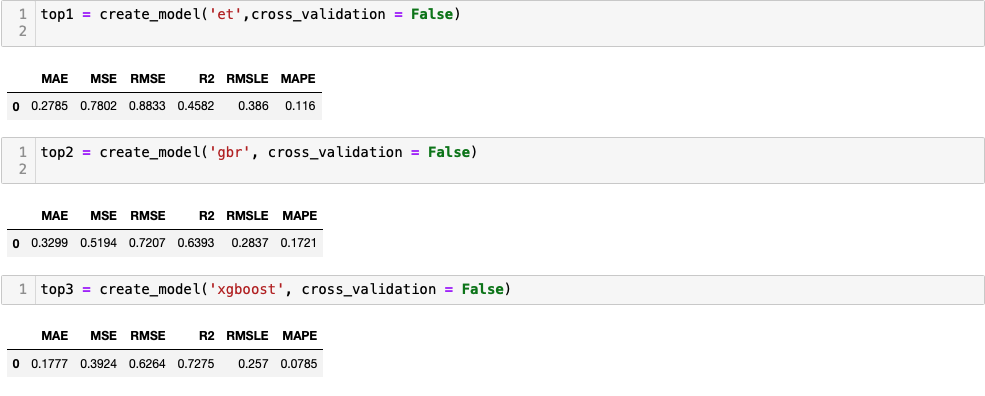
et는 Extra Trees Regressor, gbr은 Gradient Boosting Regressor, xgboost는 Extreme Gradient Boosting입니다! 여기서도 XGBoost를 보네요. 이제 여러분들도 좀 반가우시죠?ㅎㅎㅎ
아무튼, 이렇게 여러 개의 모델을 만든 이유는 뒤에 과정에서 확인하실 수 있습니다!
5. 파라미터 튜닝
사실 저희는 pycaret을 활용해서 코드 한 줄로 모델을 만들었지만, 원래는 각 모델마다 들어가는 파라미터가 많아요. xgboost 만 예를 들어도, xgboost.XGBRegressor(n_estimators=100, learning_rate=0.08, gamma=0, subsample=0.75, colsample_bytree=1, max_depth=7)
이렇게 많은 파라미터가 있어요! 그치만 파이캐럿은 이 파라미터 튜닝도 알아서 잘 해줍니다 ;)
tuned_et = tune_model(top1, optimize = 'RMSE', n_iter = 10)
tuned_gbr = tune_model(top2, optimize = 'RMSE', n_iter = 10)
tuned_xgb = tune_model(top3, optimize = 'RMSE', n_iter = 10)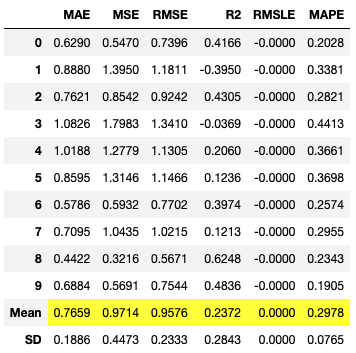
-
역시나 한 줄짜리 코드로 정리 가능합니다! n_iter는 train 데이터셋 반복 횟수로, 디폴트값이 10회입니다.
이렇게 튜닝을 실행하면, 모델별로 파라미터를 튜닝해서 검증한 결과를 보여줍니다!
-
6. 모델 블렌딩
자, 이제 저희가 가장 효과적인 하나의 모델만을 생성하지 않고, top3의 모델을 생성한 이유가 나옵니다! 파이캐럿에는 모델 블렌딩 기능도 있는데, 앞서 생성한 모델들을 블렌딩하여 더 효과적인 모델을 만드는 기능입니다! (WoW)
blender_specific = blend_models(estimator_list = [tuned_et, tuned_gbr, tuned_xgb],optimize = 'RMSE')
-
여기서 사용하는 함수는 blend_models()로, 모델이 복수! 헷갈리지 마세요ㅎㅎ(사실 제가 헷갈렸거든요)
역시나 모델을 블렌딩해서 검증까지 마친 결과를 보여줍니다!
마지막 평균값을 확인하면 조금 값이 떨어진 것을 볼 수 있죵?
7. 학습 및 예측
그럼 저희가 궁극적으로 목표했던! 학습과 예측 단계로 넘어가겠습니다. 우리가 이렇게 모델을 만들고, 비교하고, 파라미터를 튜닝하고, 블렌딩한 이유는 조금이라도 더 정확한 학습과 예측을 가능하게 하기 위해서인거니까요!
final_model = finalize_model(blender_specific)
pred = predict_model(final_model, data=KJ)이렇게 최종 모델을 만들고, 예측까지 진행해주면 됩니다! 이렇게 예측 결과가 나온 데이터 pred를 확인해볼까요?(앞에서 연속형 변수를 만들며 컬럼이 너무 많아져버려서, 보기좋게 선택하여 표현했습니다!)


여기에 실제값(result_pts) 과 예측값(Label)의 차이의 절댓값을 보여줄 수 있는 minus 열을 추가했어요. 또, 이 minus값이 1보다 작다면 잘 예측한 값이고, 1을 넘는다면 예측하지 못한 값이라고 판단해서 1을 기준으로 Good/Cross the line 각각의 라벨을 달아주었어요!(여기서 판단의 기준이 궁금하시다면 댓글 달아주세요^_<)
#실제값 - 예측값 의 절댓값 구하기
for i in range(0,len(pred)):
pred['minus'][i] = abs(pred['result_pts'][i]-pred['Label'][i])#minus행이 1을 넘는지 안넘는지 확인하는 열 추가하기
for i in range(0,len(pred)):
if pred['minus'][i] >= 1:
#print('Yes')
pred['Over'][i] = 'Cross the line'
else:
#print('No')
pred['Over'][i] = 'Good'
어떤가요! 위에 15개의 데이터만 보았는데도 나름 잘 예측한 것 같죠?ㅎㅎ
앞으로 이 파이캐럿을 충분히 활용하면 연구에도 큰 도움이 될 것 같아요. 코드도 복잡하지 않아서, 많은 분들이 이 글을 보시고 함께해주셨으면 좋겠네요!
그럼 바이~비 와이 이~(feat.매드몬스터)
'Dev > python' 카테고리의 다른 글
| 회귀분석 모델링 오답노트 . txt (0) | 2022.08.14 |
|---|---|
| 이제 그만 XGBoost를 놓아주어야 할 때가 온 것 같아요… (0) | 2022.08.10 |
| 파란만장 pycaret 설치기 / pip install pycaret error / 2022 업데이트..! (0) | 2022.08.05 |
| XGBoost는 과연 얼마나 정확했을까요? (0) | 2022.08.05 |
| 날씨, 요일, 경기장에 따라 XGBoost로 분석한 승부 예측 (0) | 2022.08.05 |



