옛날 글 보니까 오랜만에 파이썬이 너무 하고싶어졌🥹
XGBoost가 내 미래도 예측해줬으면 좋겠다..
안정적인 데이터 수집/관리 시스템을 갖춰가고 있는 현재, 저희는 경기력을 측정할 수 있는 저희만의 지수들과 경기를 예측할 수 있는 모델들을 연구하고 개발하고 있습니다!
그 중, 저는 파이썬의 XGBoost라는 부스팅 기법을 활용하여 승부를 예측할 수 있는 알고리즘 모델을 만들어 보았습니다!
(설명봇 두둥등장) XGBoost란, eXtreme Gradient Boosting 의 약자로, 여러개의 약한 의사결정 나무를 조합하여 사용하는 앙상블 기법 중 하나인 부스팅을 이용하여 구현한 알고리즘이 병렬 학습이 지원되도록 구현한 라이브러리 입니다!
저는 Jupyter notebook을 사용하고 있고, 사내 SQL 데이터 베이스에서 바로 데이터를 불러와 분석해보았습니다. 그럼 바로 함께 보실까요!
1. DB에서 데이터 불러오기
먼저 분석에 사용 될 데이터를 불러오기로 합니다! 사실 학습에 많은 변수들이 포함되면 정확도가 더 높아질테지만, 경기를 예측하는 데에 있어 저희가 수집할 수 있는 데이터들이 한정적이라, 저는 이번 예측에 날씨와 홈/원정경기, 경기가 열리는 요일 세가지 변수를 사용하였습니다! 이 데이터들은 league_data 내에 모두 포함되어있기 때문에 DB에서 불러오도록 합니당.
import pandas as pd
import pymysql
from sqlalchemy import create_engine
pymysql.install_as_MySQLdb()
import MySQLdb
import numpy as npimport warnings
warnings.filterwarnings(action='ignore')db_connection_str = 'mysql:~db정보~'
db_connection = create_engine(db_connection_str)df = pd.read_sql('''
SELECT *
FROM league_data
''', \
con=db_connection)df뒤에서 사용할 판다스나 넘피, 경고 무시 라이브러리까지 한꺼번에 import 해주었습니다! db정보를 넣고 데이터를 불러와주면, df에 무사히 데이터가 불러와진것이 확인됩니다ㅎㅎ

저는 K리그 19라운드의 경기들을 예측할 예정이기 때문에, raw데이터에서 필요한 리그, 필요한 팀, 필요한 변수만 가져오도록 하겠습니다!
#필요한 컬럼만 뽑기
raw = df[['team', 'date', 'round','competition','home','away','weather','result_pts']]#리그별로 나누기(리그데이터에 한꺼번에 들어가있음)
KL = raw[raw["competition"] == "Korea Republic. K League 1"]
JL = raw[raw["competition"] == "Japan. J1 League"]#팀별로 나누기
Daegu = KL[KL["team"] == "Daegu"]
Jeonbuk = KL[KL["team"] == "Jeonbuk Motors"]
...
Suwon = KL[KL["team"] == "Suwon"]필요한 변수에는 팀명, 경기 일자, 리그명, 홈팀, 어웨이팀, 날씨, 승점이 있습니다!
승무패를 표현한 ‘result’ 컬럼도 있는데 왜 승점으로 하나요? 라고 물으신다면, 대답해 드리는게 인지상정! XGBoost를 통해 모델을 학습시키고 예측하려면, 연속형 변수여야 합니다. 즉 숫자로 표현이 되어야 한다는 것이죠! 그래서 W, D, L로 표현된 result 컬럼이 아니라, 3,1,0으로 표현된 result_pts로 사용했습니다!
추후 편의를 위해 K리그, 각 팀으로 데이터를 나누면, raw데이터에 대한 전처리는 끝납니다!
2. Train, Test 데이터를 나누고 처리하기
이제 학습을 위한 Train 데이터와 예측을 위한 Test 데이터를 나누고 처리해보겠습니다. Train 데이터는 지금까지 진행된 라운드의 경기 데이터를 그대로 팀별로 넣어주고 전처리 해주면 되기 때문에 간단합니다! 그래서 반복문을 통해 바로 처리해주도록 했고, 각 팀의 19라운드에 대한 경기 데이터는 현재 DB에 없기때문에, 각 팀별로 하나씩 만들어줘야 합니다,,,길고 긴 수작업의 과정을 보시져!
#기본 정보 담기
test_j = pd.DataFrame([{'team' : 'Jeonbuk Motors',
'date' : '2021-05-29',
'round' : 19,
'competition' : 'Korea Republic. K League 1',
'home' : 'Incheon United',
'away' : 'Jeonbuk Motors',
'weather' : 'Sunny'}])#문자형 변수 연속형으로 바꿔주기test_j = pd.get_dummies(columns=['weather'], data = test_j)
test_j['if_home'] = np.where(test_j['home'] != 'Jeonbuk Motors', 0, 1)
test_j = test_j.reset_index()
test_j = test_j.drop(['index'], axis=1)
test_j['date'] = pd.to_datetime( test_j['date'] )
test_j['weekday'] = test_j['date'].dt.weekday
test_j['weather_Cloudy'] = 0
test_j['weather_Raining'] = 0test_j일단 DataFrame 형식으로 19라운드에 해당되는 기본 정보를 담아줍니다! 그리고 앞서 말했듯, 학습과 예측을 위해서는 연속형 변수가 필요하기 때문에 날씨나 요일 정보를 연속형으로 바꿔줍니다. numpy 라이브러리의 get_dummies를 활용해주었습니다!(이름 너무 귀엽지않나요..?겟 더미스!)
이렇게 연속형 처리까지 해주면, 다음과 같은 Test데이터가 완성됩니다. 이런 작업을 나머지 11개팀에 대해서 진행해 주면 됩니다..^_^

천년의 시간이 지나고 Test 데이터가 만들어졌다면, 이젠 반복문을 이용해 Train 데이터를 만들어보겠습니다!
#트레인, 테스트 데이터 리스트로 묶기test = [test_j, test_sb, test_i, test_jj, test_i, test_gj, test_gw, test_fcs, test_sn, test_p, test_u, test_u, test_sfc]train_t = [Jeonbuk, Suwon_B, Jeju, Incheon, Gwangju, Gangwon, Seoul, Seongnam, Pohang, Ulsan, Suwon]#Cloudy 없는 지표들 추가해주기
cloudy = [Jeju, Gangwon,Gwangju, Seoul, Seongnam, Ulsan]for i in range(len(cloudy)):
cloudy[i]['weather_Cloudy'] = 0TeamName = ['Daegu','Jeonbuk Motors', 'Suwon Bluewings', 'Jeju United',
'Incheon United', 'Gwangju', 'Gangwon', 'Seoul', 'Seongnam',
'Pohang Steelers', 'Ulsan Hyundai', 'Suwon']
test_p = []for i in range(len(TeamName)):
train = train_t[i]
train = pd.get_dummies(columns=['weather'], data = train)
#print(train)
train['if_home'] = np.where(train['home'] != TeamName[i], 0, 1)
train = train.reset_index()
train = train.drop(['index'], axis = 1)
train['date'] = pd.to_datetime(train['date'])
train['weekday'] = train['date'].dt.weekday
input_var = ['weather_Cloudy', 'weather_Raining','weather_Sunny','weekday','if_home']
...for 문을 활용하여 간단하게 Train 데이터를 완성했습니다!

그럼 이제 바로 학습시키고 예측 결과를 뽑아볼까용?
...(반복문 계속)
xgb = XGBRegressor(n_estimators = 200, learning_rate = 0.1, random_state = 2000)
xgb.fit(train[input_var], train['result_pts'])test[i]['result_P'] = xgb.predict(test[i][input_var]) if 2 <= test[i]['result_P'].item() < 3:
test[i]['Prediction'] = 'WIN'
elif 1 <= test[i]['result_P'].item() < 2:
test[i]['Prediction'] = 'DRAW'
elif 0 <= test[i]['result_P'].item() < 1:
test[i]['Prediction'] = "LOSE"
test_p.append(test[i])이렇게 result_P라는 변수에 예측된 승점을 담아주고, 그 변수를 활용하여 다시 문자로 표현해주겠습니다! 0~1사이의 값은 Lose로 예측, 1~2사이의 값은 Draw로 예측, 2~3사이의 값은 Win으로 예측하였습니다! 그랬더니, 짜잔~!
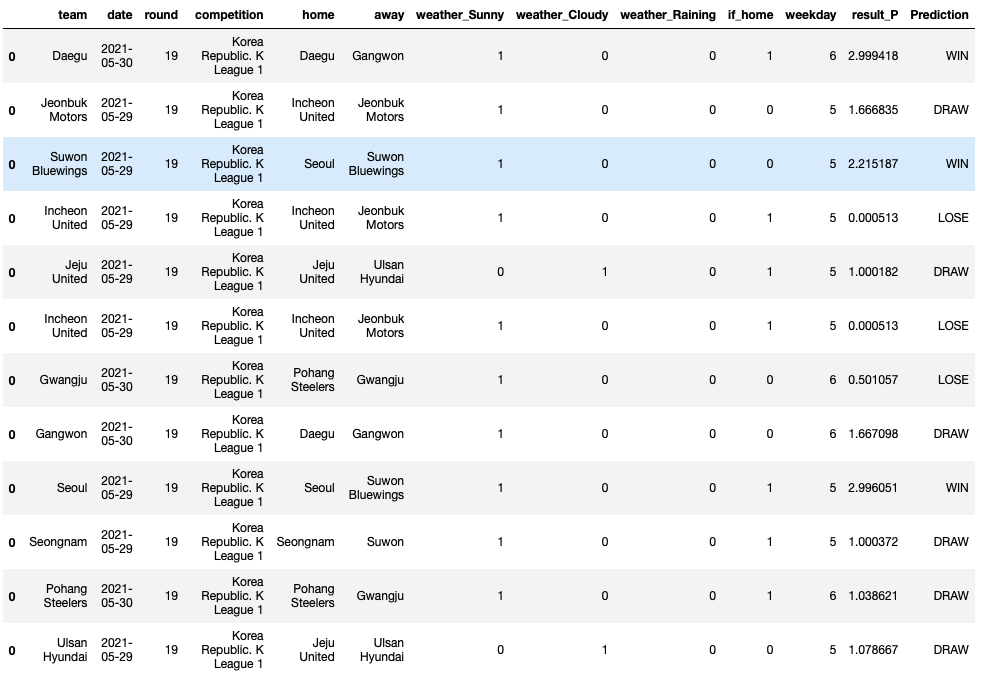
이렇게 승부를 예측해주었어요! (xgb야 내 미래도 예측해주라)
이번 주말, 저는 19라운드 경기를 살펴보며 xgb의 정확도를 지켜보도록 하겠습니다! 👀 함께 지켜봐주세요👀!
'Dev > python' 카테고리의 다른 글
| 파란만장 pycaret 설치기 / pip install pycaret error / 2022 업데이트..! (0) | 2022.08.05 |
|---|---|
| XGBoost는 과연 얼마나 정확했을까요? (0) | 2022.08.05 |
| 다시 돌아온 취준생활, 프로젝트 정리 (0) | 2021.10.28 |
| 추가! 나의 파이썬 공부기록 (0) | 2021.10.27 |
| 당신의 픽에 투표하세요! 픽미픽미 나야 나! sorting을 통해 만들어보는 조합 픽 (0) | 2021.10.27 |



